Here, we will try to classify Bangla news contents with an LSTM network. Bangla is a diverse and complex language. The dataset contains 400k+ Bangla news samples of 25+ categories. We will reach 91% test accuracy for our simple LSTM model.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport picklefrom collections import Counter
import jsonwith open('data.json', encoding='utf-8') as fh:data = json.load(fh)
{'author': 'গাজীপুর প্রতিনিধি', 'category': 'bangladesh', 'category_bn': 'বাংলাদেশ', 'published_date': '০৪ জুলাই ২০১৩, ২৩:২৬', 'modification_date': '০৪ জুলাই ২০১৩, ২৩:২৭', 'tag': ['গাজীপুর'], 'comment_count': 0, 'title': 'কালিয়াকৈরে টিফিন খেয়ে ৫০০ শ্রমিক অসুস্থ, বিক্ষোভ', 'url': 'http://www.prothom-alo.com/bangladesh/article/19030', 'content': '...'}
z = zip(cat_cnts, set_cats)z = list(z)
z
[(83, 'nagorik-kantho'),(859, 'special-supplement'),(7402, 'durporobash'),(1, 'bs-events'),(508, 'kishoralo'),(15699, 'opinion'),(2, 'events'),(990, 'bondhushava'),(11, '22221'),(49012, 'sports'),(1, 'AskEditor'),(10, 'facebook'),(17, 'mpaward1'),(6990, 'northamerica'),(40, 'tarunno'),(10852, 'life-style'),(3443, 'pachmisheli'),(123, '-1'),(30856, 'international'),(232504, 'bangladesh'),(2604, 'roshalo'),(17245, 'economy'),(2999, 'we-are'),(75, 'chakri-bakri'),(9721, 'education'),(30466, 'entertainment'),(2702, 'onnoalo'),(2, 'diverse'),(443, 'trust'),(170, 'protichinta'),(2, 'demo-content'),(12116, 'technology')]
sel_cats = []for p in z:if p[0] > 8000:sel_cats.append(p[1])
sel_cats
['opinion','sports','life-style','international','bangladesh','economy','education','entertainment','technology']
X_text = []y_label = []for p in data:if p['category'] in sel_cats:y_label.append(p['category'])X_text.append(p['content'])
len(X_text)
408471
len(y_label)
408471
from sklearn.preprocessing import LabelEncoderencoder = LabelEncoder()class_labels = encoder.fit_transform(y_label)
from sklearn.preprocessing import OneHotEncoderencoder = OneHotEncoder(sparse=False)class_labels = class_labels.reshape((class_labels.shape[0], 1))y_ohe = encoder.fit_transform(class_labels)
from keras.preprocessing.text import Tokenizertokenizer = Tokenizer()tokenizer.fit_on_texts(X_text)X_token = tokenizer.texts_to_sequences(X_text)vocab_size = len(tokenizer.word_index) + 1 # Adding 1 because of reserved 0 index
from keras.preprocessing.sequence import pad_sequencesmaxlen = 300X_pad = pad_sequences(X_token, padding='post', maxlen=maxlen)
from keras.models import Sequentialfrom keras.layers import Embedding, CuDNNLSTM, Bidirectional, Denseembedding_dim = 8model = Sequential()model.add(Embedding(input_dim=vocab_size,output_dim=embedding_dim,input_length=maxlen))model.add(Bidirectional(CuDNNLSTM(128, return_sequences = True)))model.add(Bidirectional(CuDNNLSTM(128)))model.add(Dense(9, activation='softmax'))model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])model.summary()
_________________________________________________________________Layer (type) Output Shape Param #=================================================================embedding_7 (Embedding) (None, 300, 8) 19307592_________________________________________________________________bidirectional_13 (Bidirectio (None, 300, 256) 141312_________________________________________________________________bidirectional_14 (Bidirectio (None, 256) 395264_________________________________________________________________dense_7 (Dense) (None, 9) 2313=================================================================Total params: 19,846,481Trainable params: 19,846,481Non-trainable params: 0_________________________________________________________________
import numpy as npfrom sklearn.model_selection import StratifiedShuffleSplitsss = StratifiedShuffleSplit(n_splits=2, test_size=0.3, random_state=0)sss.get_n_splits(X_pad, y_ohe)#print(sss)for train_index, test_index in sss.split(X_pad, y_ohe):#print("TRAIN:", train_index, "TEST:", test_index)X_train, X_test = X_pad[train_index], X_pad[test_index]y_train, y_test = y_ohe[train_index], y_ohe[test_index]
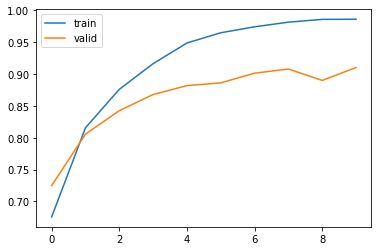
history = model.fit(X_train, y_train,epochs=10,verbose=1,validation_split=0.2,batch_size=256,class_weight = class_weight)Train on 228743 samples, validate on 57186 samplesEpoch 1/10228743/228743 [==============================] - 97s 424us/step - loss: 8.3862 - acc: 0.6757 - val_loss: 6.4694 - val_acc: 0.7250Epoch 2/10228743/228743 [==============================] - 98s 428us/step - loss: 4.9663 - acc: 0.8157 - val_loss: 5.6947 - val_acc: 0.8057Epoch 3/10228743/228743 [==============================] - 98s 428us/step - loss: 3.0535 - acc: 0.8760 - val_loss: 4.6644 - val_acc: 0.8425Epoch 4/10228743/228743 [==============================] - 98s 431us/step - loss: 1.7724 - acc: 0.9164 - val_loss: 4.2003 - val_acc: 0.8679Epoch 5/10228743/228743 [==============================] - 99s 431us/step - loss: 1.0102 - acc: 0.9488 - val_loss: 4.4401 - val_acc: 0.8819Epoch 6/10228743/228743 [==============================] - 99s 431us/step - loss: 0.5970 - acc: 0.9649 - val_loss: 4.8751 - val_acc: 0.8862Epoch 7/10228743/228743 [==============================] - 99s 431us/step - loss: 0.4106 - acc: 0.9742 - val_loss: 4.8832 - val_acc: 0.9014Epoch 8/10228743/228743 [==============================] - 99s 432us/step - loss: 0.2760 - acc: 0.9815 - val_loss: 5.7314 - val_acc: 0.9080Epoch 9/10228743/228743 [==============================] - 99s 432us/step - loss: 0.2167 - acc: 0.9859 - val_loss: 5.8225 - val_acc: 0.8900Epoch 10/10228743/228743 [==============================] - 101s 440us/step - loss: 0.2202 - acc: 0.9861 - val_loss: 5.9164 - val_acc: 0.9103
plt.plot(history.history['acc'])plt.plot(history.history['val_acc'])plt.legend(['train', 'valid'])plt.show()